We Trained the Ukrainian Language Model

YouScan is a social media monitoring company that always stays at the cutting edge of technology to provide the best AI-based solutions for our customers. We wanted to make our contribution to Open Source and released the Ukrainian language model that was trained by our data science team.
We have recently published articles about our sentiment classification and aspects classification, in which we described the results that we had achieved thanks to their Open Source nature and modern technology.
Then we decided to keep on exploring Open Source, so we trained the Ukrainian language model on 30Gb data from multiple sources (social media, news and Wikipedia) and tried to make it applicable for different tasks.
Pretraining details
Ukrainian RoBERTa was trained with the code provided in the HuggingFace tutorial
The currently released model follows roberta-base-cased model architecture (12-layer, 768-hidden, 12-heads, 125M parameters)
The model was trained on 4xV100 (85 hours)
Training configuration you can find on our github page
Evaluation
ukr-roberta-base was tested on internal YouScan tasks. We achieved an average increase of 2 percent (fscore) compared to mBERT on multiclass and multilabel classification tasks.
Usage
You can use this model for a language modeling task or fine-tune it for any other task. We provided all model weights and vocabulary for correct usage, but the most comfortable way is to use it via the HuggingFace Transformers library as demonstrated in the example below:
from transformers import pipeline, RobertaForMaskedLM, RobertaTokenizer
model = RobertaForMaskedLM.from_pretrained("ukr-roberta-base")
tokenizer = RobertaTokenizer.from_pretrained("ukr-roberta-base")
fill_mask = pipeline(''fill-mask'', model=model, tokenizer=tokenizer)
fill_mask("Тарас Шевченко – великий український <mask>.")
# [{'sequence': '<s> Тарас Шевченко – великий український поет.</s>',
# 'score': 0.48607954382896423,
# 'token': 11426},
# {'sequence': '<s> Тарас Шевченко – великий український письменник.</s>',
# 'score': 0.23330871760845184,
# 'token': 10121},
# {'sequence': '<s> Тарас Шевченко – великий український художник.</s>',
# 'score': 0.06583040952682495,
# 'token': 12836},
# {'sequence': '<s> Тарас Шевченко – великий український князь.</s>',
# 'score': 0.021497823297977448,
# 'token': 17247},
# {'sequence': '<s> Тарас Шевченко – великий український народ.</s>',
# 'score': 0.020411811769008636,
# 'token': 1021}]
Moreover, you can test it directly on our HuggingFace model page.
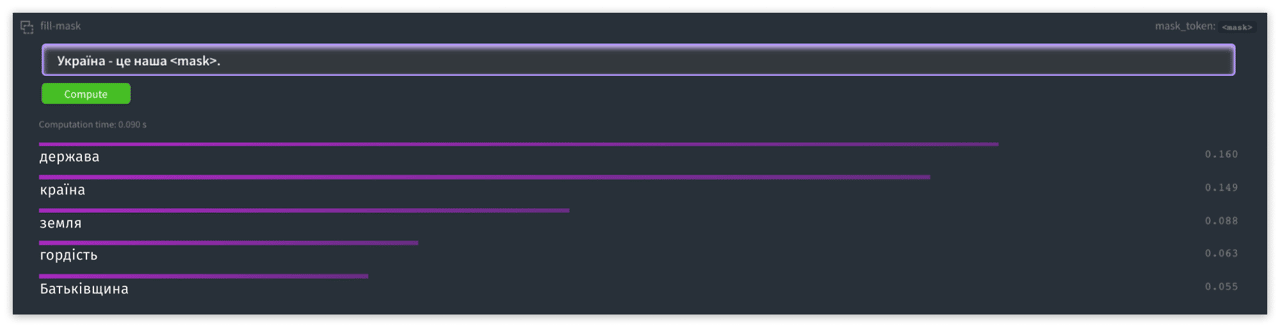
We hope that our experience will help other NLP researchers and practitioners build their expertise in the Ukrainian language. If you have any questions or need any help, feel free to contact us.