Один день из жизни дата-сайентиста

Или небольшая история о том, как мы создаем и тренируем новые алгоритмы машинного обучения для анализа данных из соцсетей…

Мы в YouScan применяем технологии «искусственного интеллекта», работаем с данными, и все задачи по поиску и аналитике трендов в соцсетях выполняют алгоритмы машинного обучения. Чтобы извлечь из данных ценную информацию необходимо провести подготовительную работу. Эти задачи решают дата-сайентисты (data scientist), и мы решили рассказать о том, чем они занимаются, и как проходит обычный день дата-сайентиста в YouScan.
Дата-сайентист …из названия профессии само собой разумеется, что основной объект, с которым сталкивается специалист данной категории – это данные. Но далеко не все представляют, как много времени занимает обработка первичных источников. Дата-сайентисты до 80% своих ресурсов тратят на то, чтобы подготовить так называемые «сырые данные» — то есть неструктурированные лавины сообщений – никак не обработанных и не проанализированных.
Современный «искусственный интеллект» условно называют «слабым» – ведь он пока не может реагировать на непредвиденные ситуации и требует отдельного цикла машинного обучения для каждой конкретной задачи.
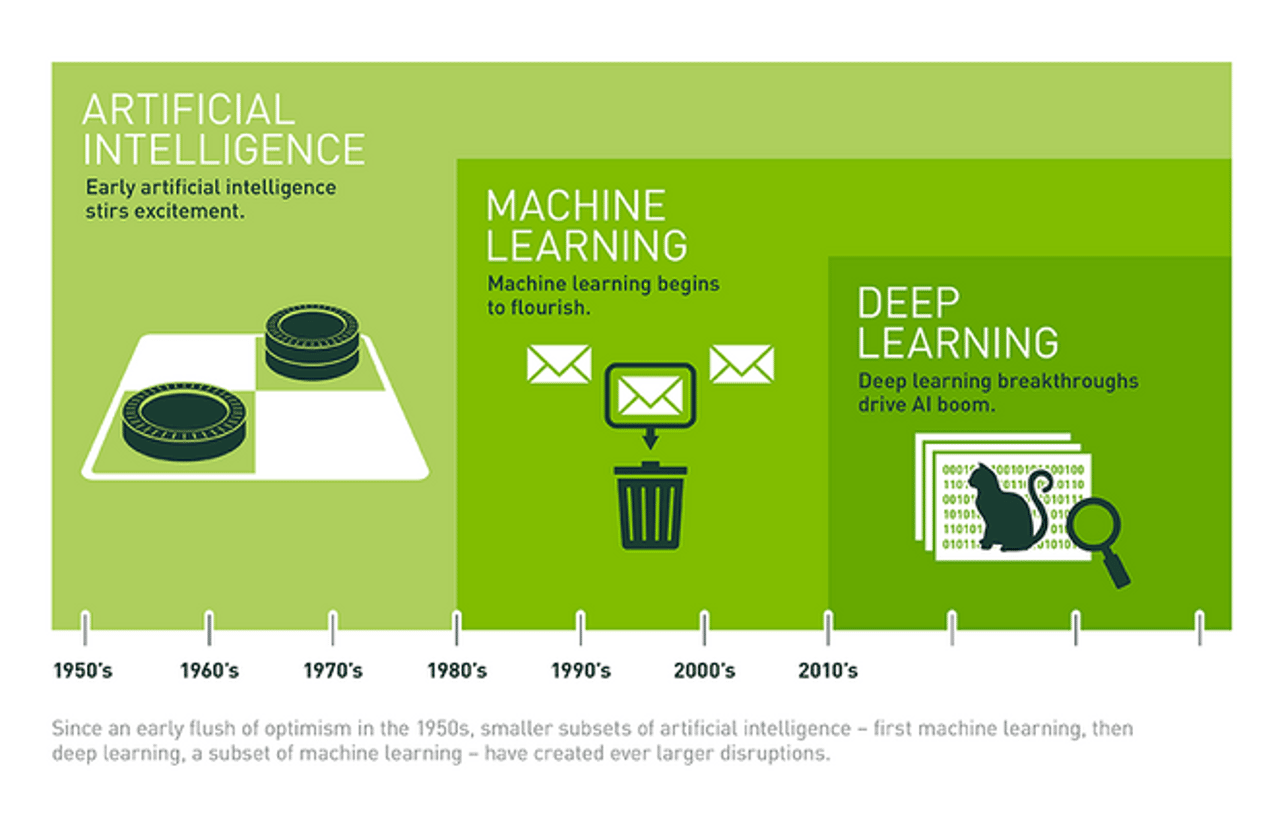
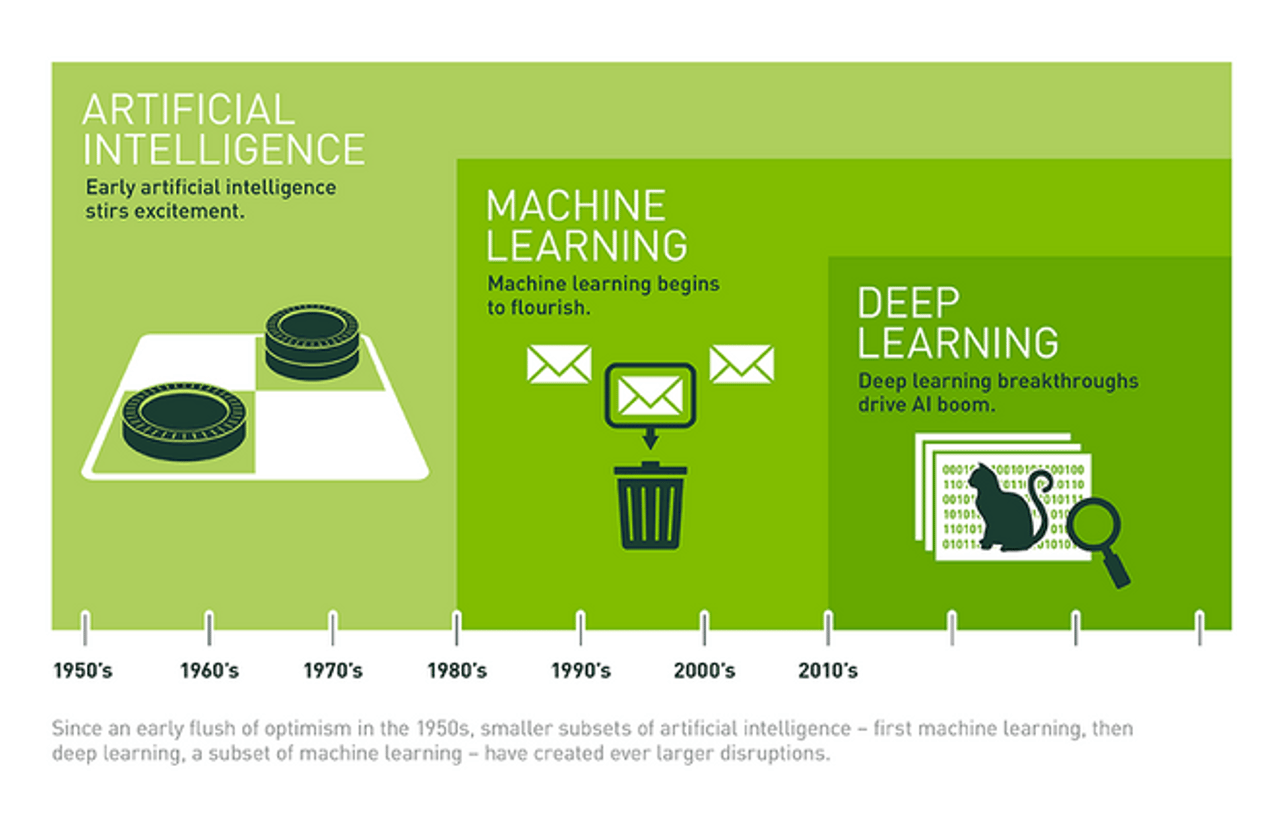
Все «зимы» (по сути, застои в развитии) ИИ были связаны с разочарованием из-за завышенных ожиданий индустрии в его отношении. Так, после активного старта развития в 1960-х многие ученые верили в возможность построения универсальных роботов уже через несколько десятков лет.
Сегодня ИИ скорее дополняет возможности человеческого разума, а не заменяет его за счет того, что специально разработанные наборы алгоритмов помогают решать объемные задачи. «Тренировкой» этих алгоритмов как раз занимаются дата-сайентисты. Иногда им достаются уже понятные задачи, где данные предварительно разбиты на классы, например, уже известны гендерные признаки аудитории или возрастные характеристики. Но чаще всего работать приходится с данными, в которых нет никакой структуры. Дата-сайентистам приходится искать закономерности, делать гипотезы и проверять их на практике.
Наш отдел дата-сайентистов
В нашем отделе дата-сайентистов работает 6 человек. Все они, естественно, математические гики, потому что для успеха в этой сфере нужно хотя бы на базовом уровне разбираться в теории алгоритмов, теории вероятности, математической статике, численных методах, а также уметь программировать на Python. Ребят набирали «в свободном полете» – то есть после знакомств на конференциях, в специализированных чатах, по рекомендации – но всегда с учетом их увлеченности темой. Все они вели проекты на GitHub, активно комментировали вопросы DS на форумах, а также были участниками всевозможных хакатонов, конференций, соревнований и так далее.
Руководитель отдела – Евгений Терпиль. Он работает дата-сайентистом уже около 3 лет, и на его счету десятки готовых моделей, помогающих решать задачи аналитики в социальных сетях. Несколько лет назад Евгений закончил Киевский политехнический институт и начал карьеру фронтенд-разработчиком. Тема Data Science «не отпускала» его еще со студенческой скамьи, и с приходом в YouScan Женя решил окончательно переквалифицироваться. Кстати, по его мнению, в основном дата-сайентистами становятся как раз бывшие разработчики.
«Стать успешным дата-сайентистом можно даже если вы не закончили специализированный вуз, но для этого нужно быть «в теме» и обладать достаточными знаниями в информатике и математике, а также действительно «болеть» data science. Так что глубокое фундаментальное образование на мой взгляд, дает соискателю массу преимуществ. А для повышения квалификации можно пройти специализированные онлайн-курсы, например, на Coursera, или принять участие в соревнованиях на платформе Kaggle, где можно тестировать свои решения, обучаться самостоятельно, – говорит Евгений, – Это хороший вариант для поиска своего места на рынке труда, ведь сегодня вакансий в сфере DS только в России и СНГ уже тысячи».
Задачи дата-сайентиста
Каждый день дата-сайентисты решают сложные задачи. В случае с YouScan они выглядят следующим образом:
Подготовка данных. Как мы уже говорили, подготовка сырых данных отнимает до 80% рабочего времени дата-сайентиста. Если никакой достоверной информации нет, данные приходится размечать вручную или запускать различные алгоритмы для предварительного анализа и оптимизации разметки данных.
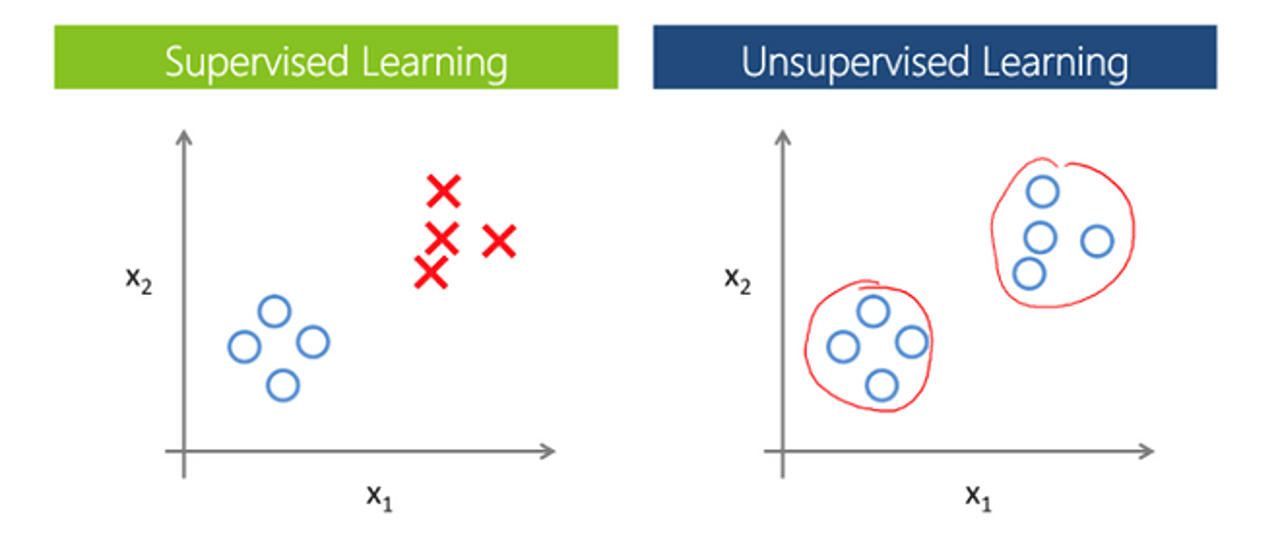
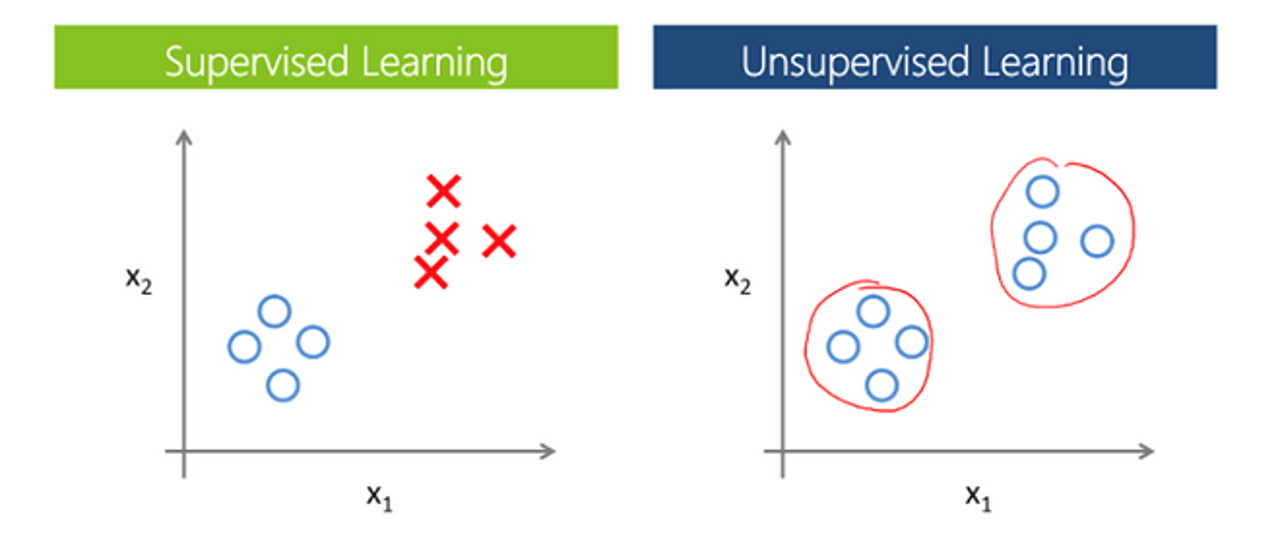
Машинное обучение алгоритмов искусственного интеллекта. Когда у команды уже есть набор размеченных данных, например, мы уже знаем, что имеющиеся у нас 100 постов – это сообщения с позитивной тональностью, дата-сайентисты обучают модель с использованием этих данных. На этом этапе важнее всего правильно выбрать подходящий алгоритм или разработать новый, опираясь на опыт мирового сообщества DS. Обучение модели происходит на основе supervised- и unsupervised-методов (по-нашему – «с учителем» и «без учителя»). Если для части данных мы наперед знаем класс, к которому они относятся, например, тональность сообщения, то мы имеем дело с обучением с учителем. Наша задача заключается в том, чтобы по небольшой выборке обучить модель различать классы. Однако чаще готовой разметки в данных просто нет. В таком случае можно использовать методы обучение без учителя, которые помогают определить структуру данных и выделить различные кластеры.
Проверка гипотез. Искусственный интеллект не может предусмотреть и тем более самостоятельно решить неизвестные ему проблемы (по крайней мере пока). Поэтому дата-сайентистам приходится проверять различные гипотезы вручную. Например, если у специалиста возникает предположение: «Не уходят ли от нас пользователи, которые не используют дополнительные функции?», — дата-сайентисты займутся проверкой этой гипотезы. Такой подход позволяет определить, действительно ли стоит уделять внимание доработке какой-то функции, или вы теряете клиентов совсем по другой причине.
Поиск закономерностей. Кроме этого можно работать не с гипотезами, а искать возможные причины каких-то событий в широком потоке информации. То есть дата-сайентисту можно поставить задачу – найти корреляцию между успехом баннеров и характеристиками содержимого графической рекламы, и он будет выявлять любые закономерности, которые могут иметь отношение к этому вопросу.
Работа дата-сайентиста во многом оказывается интуитивной и творческой. Невозможно взять и сразу предугадать все возможные особенности и характеристики наборов данных. Нередко модели приходится переосмысливать, проводить множество экспериментов и запускать альтернативные версии алгоритмов для сравнения результатов. Например, разработка каждой новой функции для нашей системы происходит в следующем порядке:
Исследование технологических возможностей. Например, мы постоянно следим за новшествами в таких сферах, как распознавание картинок или определение тональности сообщений
Проведение экспериментов. Если мы находим новый алгоритм, который оказался эффективным для определения, например, возраста человека на картинке, можно попробовать использовать его для определения пола. Но не факт, что это будет работать, поэтому нужно провести эксперимент.
Прототипирование. Если все предыдущие процессы прошли успешно, нужно создать сначала тестовую систему для себя самих. На этом этапе дата-сайентисты вместе с разработчиками формируют демонстрационную версию новой «фичи».
Создание готового продукта. Внедрение новинки в продукт происходит уже при участии маркетологов, дизайнеров и менеджеров по продуктам. Это нужно для того, чтобы из интересной «фичи» появилось решение, востребованное пользователями.
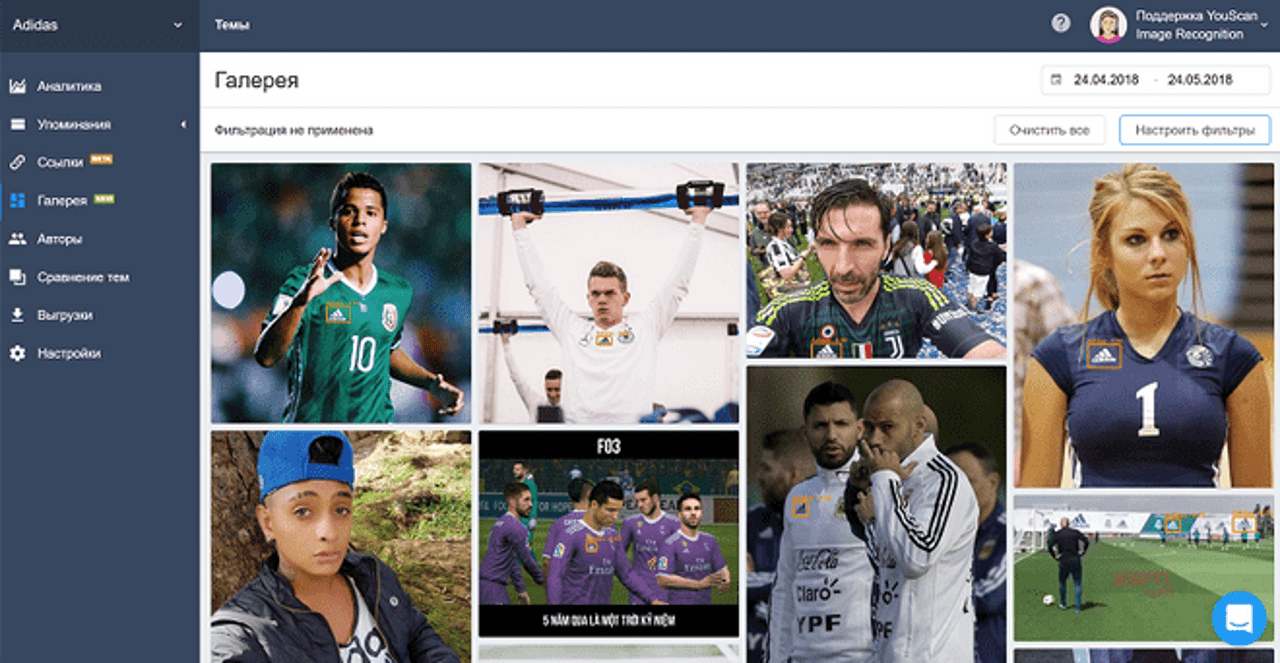
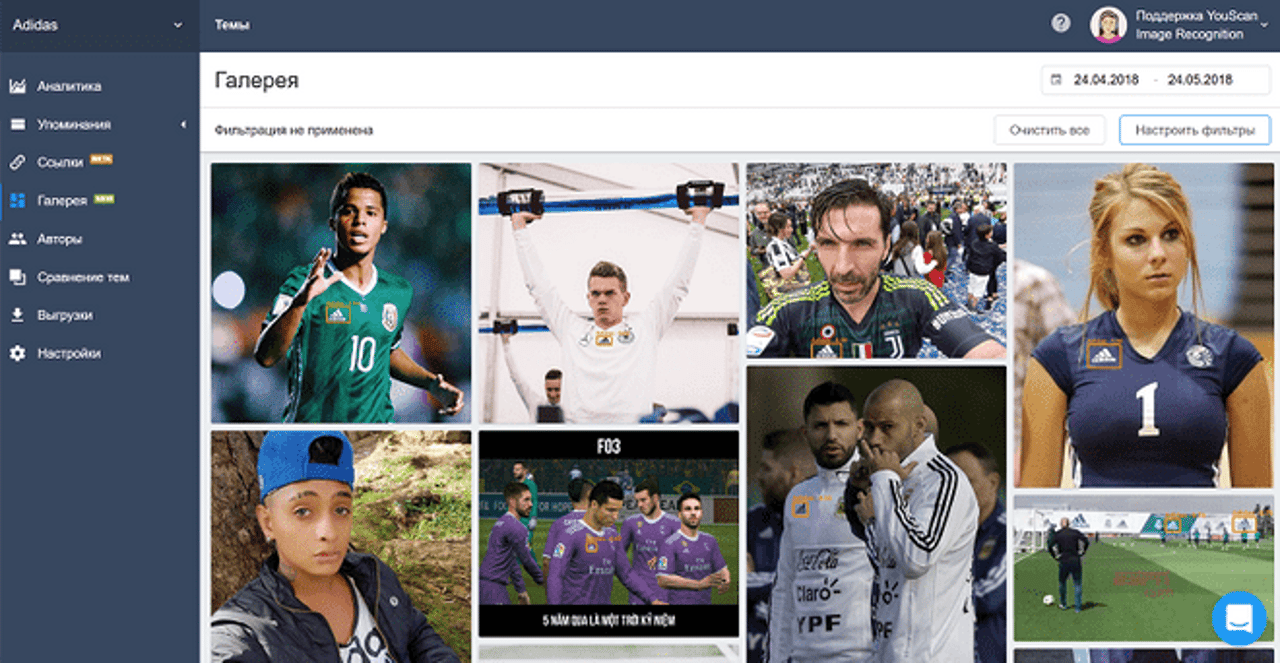
Пример одной из последних разработок наших дата-сайентистов – функция распознавания логотипов. Теперь мы можем находить упоминания бренда в соцмедиа, даже если в тексте нет его названия — достаточно, чтобы на опубликованной пользователем фотографии или картинке присутствовал логотип.
Анализ тональности
Одна из тем, с которыми работают наши дата-сайентисты – это определение тональности сообщений. Тональность, как вербальное выражение отношения к тому или иному вопросу, бывает трех типов: позитивная, нейтральная или негативная. Проблема в данном случае заключается в том, что «живой» контент из социальных сетей, с которым мы работаем, может отличаться. Бывают очень тонкие оттенки позитива или негатива, а когда пользователи прибегают к иронии или сарказму, все становится еще сложнее.
Более того, нужно анализировать контекст. Например, чистящее средство, которое хорошо отмывает посуду – это позитив, а подобное сообщение про Coca-Cola – это негатив. Ведь вряд ли производитель напитков хочет, чтобы его продукт ассоциировался с бытовой химией. Решить подобные сложности удается за счет использования глубоких нейронных сетей с рекуррентными слоями памяти. В этом случае мы ищем и разрабатываем алгоритмы, настроенные на определение особенностей контекста, объектов обсуждения и тематики.
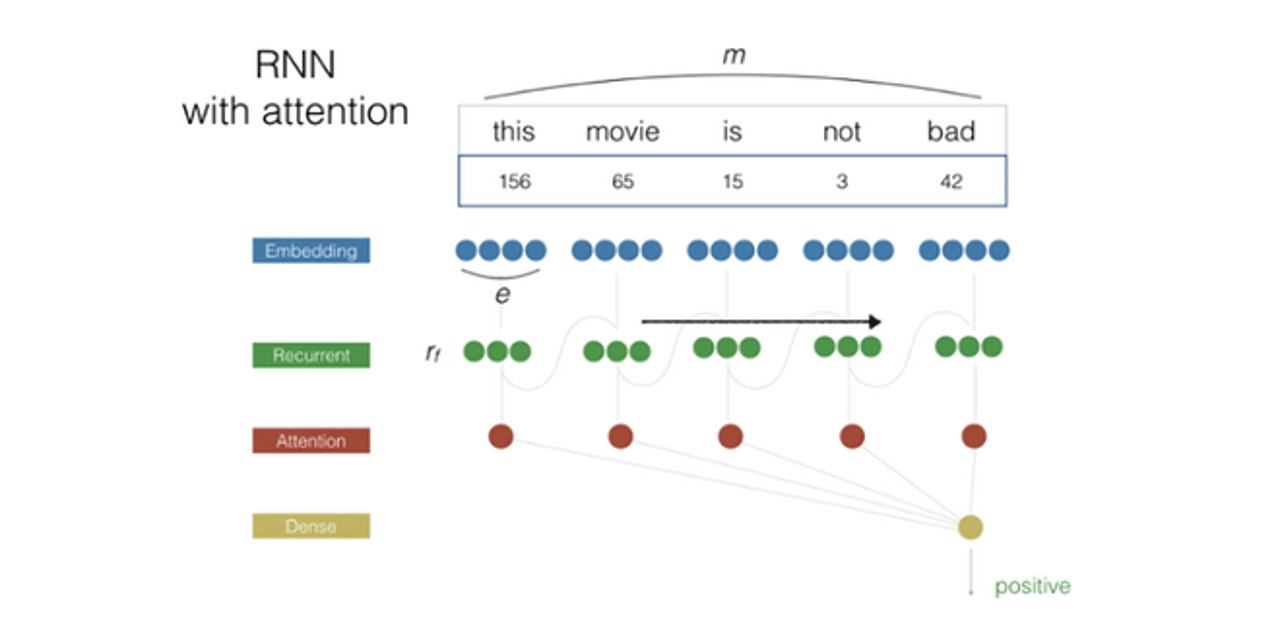
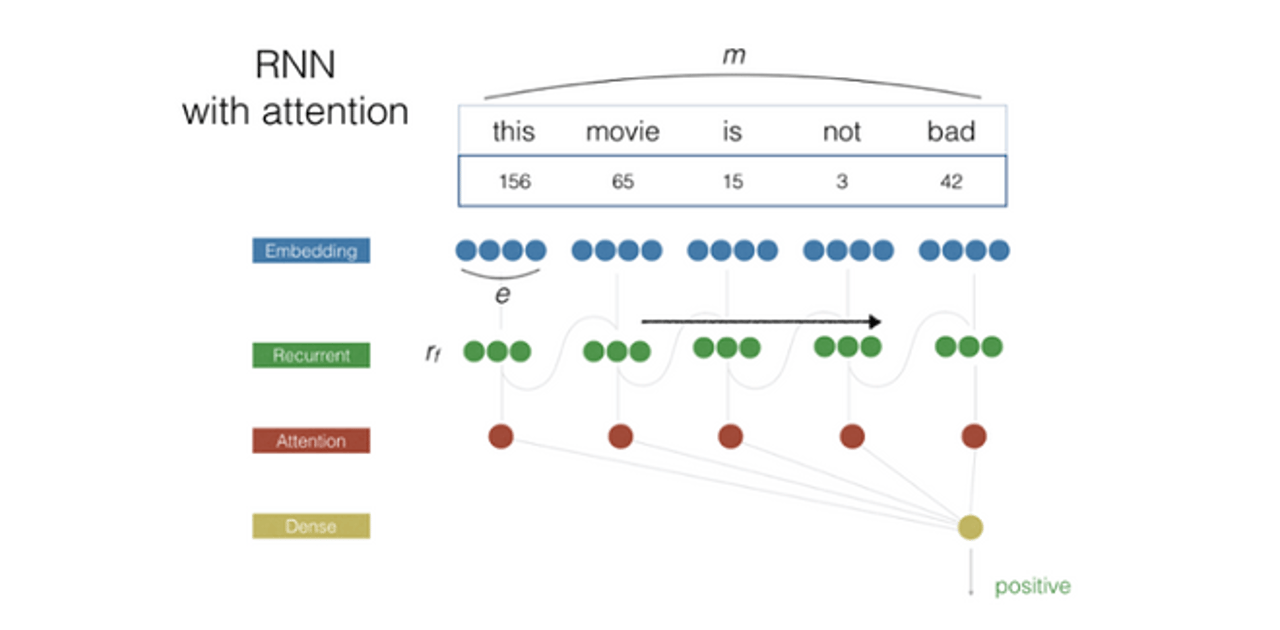
Новая модель на основе рекуррентных нейронных сетей лучше понимает специфику упоминания, за счет этого удалось уменьшить количество ошибок в несколько раз.
В этом вопросе на плечи дата-сайентистов ложится формирование большой обучающей выборки, которая позволяет научить алгоритмы понимать особенности выражения мнений в социальных сетях. Мы тренируем «машинку» определять тональность для разных категорий брендов с учетом их специфики, и теперь распознавание тональности происходит с большей точностью.
Источники вдохновения
Наши дата-сайентисты начинают свой рабочий день с кофе и с чтения англоязычных медиа, где в первую очередь публикуются самые передовые тренды и новости. Например, наши ребята находят много интересного в блогах на Medium и в статьях на arxiv.org – в архиве электронных публикаций и препринтов Корнуэльского университета. Так сложилось, что что там публикуют все самое свежее из сферы Data Science и machine learning.
Русскоязычное сообщество дата-сайентистов общается в slack-чате ODS (Open Data Science). В нем на данный момент состоит уже более 12 тысяч пользователей, которые помогают друг другу. Еще наши ребята участвуют в группе ВК Deep Learning и активно читают/комментируют вопросы своей компетенции на Habrahabr.




Интересно, что большинство научных статей от лидеров отрасли публикуются в открытом доступе. Например,Google иFacebook подробно рассказывают о своих алгоритмах и специально анонсируют самые современные модели обучения ИИ на десятках научных конференций. То есть мы можем как использовать технологии лидеров индустрии, так и адаптировать их к своим задачам – то есть анализу соцмедиа. Кстати, при аналогичном качестве распознавания изображений, нам удалось сделать стоимость таких услуг, как распознавание логотипов, в разы ниже, чем на Западе.
Усложнение задач по обработке контента продолжается каждый день. Например, уже сегодня речь идет об обучении алгоритмов анализа видео любых форматов – от историй пользователей на FB или VK до детального изучения каналов на YouTube. Ведь в сущности видео – это тот же набор картинок, которые уже успешно анализируют наши алгоритмы. Только теперь их становится больше… намного больше.
Познакомились с особенностями работы дата-сайентистов? В нашем блоге всегда много интересного, а чтобы всегда быть в курсе самых полезных материалов из мира социальных медиа, подписывайтесь на нас в социальных сетях: Facebook, Twitter, Vkontakte, Linkedin или на наш канал в Telegram.
-1669931544.png)
-1669652493.png)
-1640363177-1645191455.png)
