One Day in the Life of a Data Scientist

Or a short story about how we create and train new machine learning algorithms for social media data analysis.
At YouScan, we utilize AI technologies and work with data - and the search and analysis of social media trends are done with the help of machine learning algorithms. Extracting valuable insights from the data requires some preliminary work. This work is usually done by a data scientist. We decided to lift the curtain on what they do, how they work, and what a regular day in life of a YouScan data scientist looks like.
As you can tell by the title, the main tool of trade for data scientists is data. But not everyone knows just how much time it takes to collect and sort through primary data sources. Data scientists spend up to 80% of their resources to scrub the so-called "raw data" - or piles of unstructured information - that has not yet been processed or analyzed.
Contemporary artificial intelligence is often called "weak AI," since it cannot adequately react to unexpected situations, and demands dedicated cycles of training for each distinct task.
Historically, all AI "winters" (essentially, development plateaus) have been tied to disappointments of unreasonably high expectations from industries. As such, after a strong start in AI development in the 1960s, many researchers believed in the possibility of development of general-intelligence robots within decades.
However, today, artificial intelligence complements the potential of human cognition instead of replacing it, through a set of algorithms specifically designed to help solve complex problems. The training of such algorithms is usually done by data scientists. Sometimes the solutions are straightforward, where the data is already sorted by categories - for example, by the audience's gender and age. However, more often, the algorithms have to deal with totally unorganized raw numbers. Data scientists have to find patterns in the raw data, come up with hypotheses and test the numbers against these hypotheses.
Our data science department
Six people work in our data science department. All of them are math nerds, of course, because to succeed in this field, you need at least some basic knowledge of algorithms, probability theory, statistics, quantitative methods, and a little bit of Python coding skills. We hired our data scientists rather spontaneously - meeting them at conferences, professional chatrooms, or on recommendation - but always with consideration of their passion for this kind of work. All of them ran GitHub projects, actively participated in data science forum discussions, and also took part in various hackathons, conferences, competitions, etc.
Evgeny Terpil is the head of the data science department. He's been working as a data scientist for over three years, and he's already written dozens of completed models that can solve social media analytics problems. Several years ago, Evgeny graduated from the Kiev Polytechnic Institute and started working as a front-end developer. But data science has been his passion since his student days, and after getting hired at YouScan, Evgeny decided to change his specialization completely. By the way, he thinks that most data scientists start out as developers.
"You can be a data scientist without formal post-secondary training, but you do have to possess certain relevant skills and knowledge of computer science and math, and really live and breathe data science. So the knowledge of computer science fundamentals, in my opinion, gives the candidate many advantages. Those who seek professional development can take specialized online courses - for example, on Coursera - or participate in competitions on Kaggle, where you can test your code and learn independently," Evgeny says. "This is a great option for finding your place on the job market, where there are thousands of DS job postings around Russia and the Russian Commonwealth."
Data scientist's tasks
- Data scientists solve complex problems on a daily basis. At YouScan, they encounter the following tasks:
Data processing. As we already mentioned, processing raw data takes up to 80% of a data scientist's work day. If there isn't any trustworthy way to sort the data, it has to be marked up manually, or the data scientist has to create various algorithms for preliminary analysis and markup optimization.
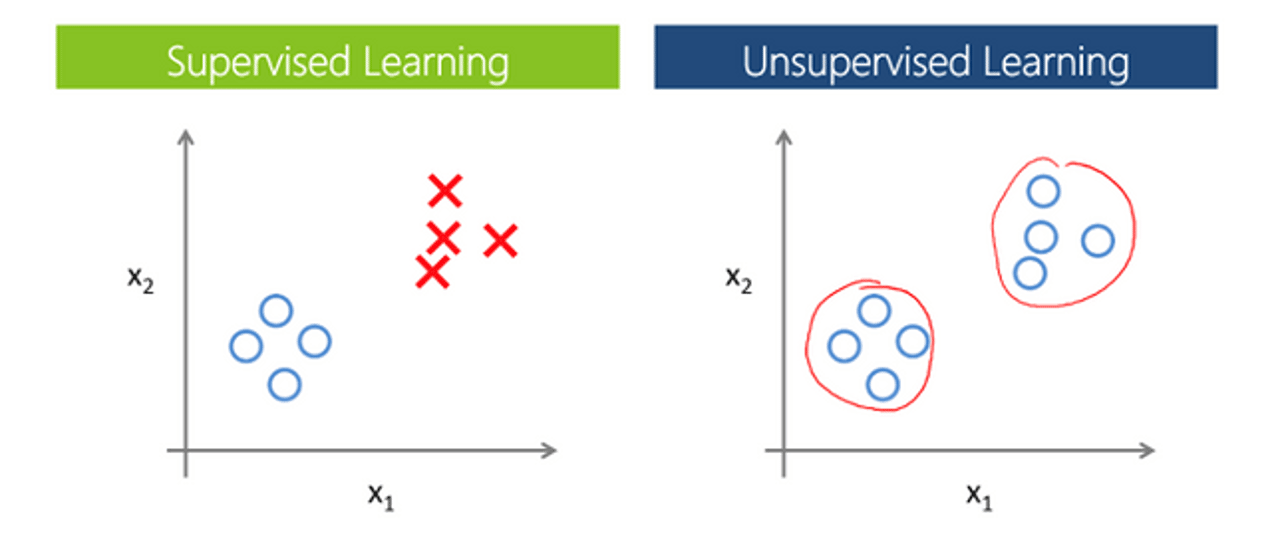
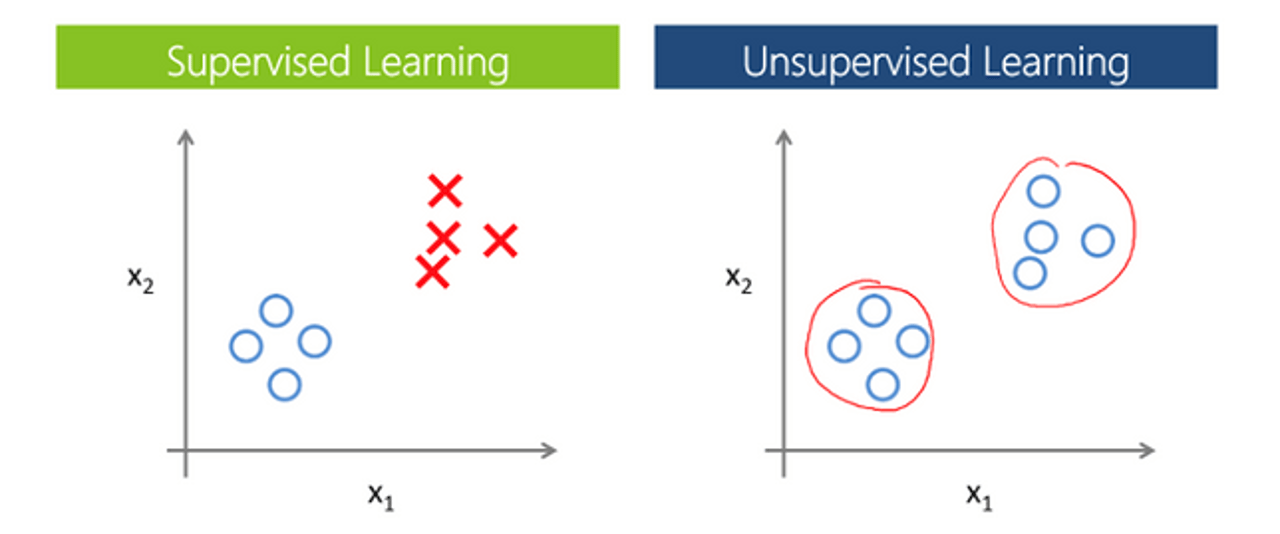
Machine learning for AI algorithms. When the team has a processed data set - for example, if we already know that the 100 posts we're working with contain positive sentiment - data scientists then train their AI model using these 100 posts. At this stage, it's very important to choose the right algorithm, or tap into the international DS community to help write a new algorithm. Training occurs using both supervised- and unsupervised-learning methods. If we already know the category for some of the data - which includes post sentiment in our example - then we're dealing with supervised learning. Our goal is to teach the AI to distinguish between categories based on a small data set. However, more often than not, there is no available data set that can be used for training. In this case, you can use unsupervised learning methods, which help determine the data structure and form various clusters.
Testing hypotheses. AI cannot predict or independently solve unknown problems (not yet, anyway). That's why data scientists have to test their hypotheses themselves. For example, if we wonder, "Are users that don't take advantage of all the additional features leaving us?"— data scientists can test this hypothesis. This approach allows us to determine whether or not to dedicate time and resources to the development of certain functions, or if you're losing clients for some other reason.Searching for patterns. Besides hypotheses and tests, data scientists can also look for patterns in certain events in a wide information stream. For example, you can assign a data scientist to look for a correlation between banner success rate and the content of banner ads, and they will look for any patterns relevant to this query.
A data scientist's job can be very creative. One simply cannot predict all the possible quirks and inconsistencies of a data set. Data scientists often have to reevaluate models, conduct numerous experiments and launch different versions of an algorithm to compare results.
- For example, the development of each new software feature unfolds in the following order:
Innovation research. We try to keep up with the latest developments in image recognition or sentiment analysis software.
Experimentation. If we find a new algorithm that proves effective for detecting such things as the approximate age of a person in a photo, we try to see if we can use the same algorithm to detect gender. There's no guarantee that it will work in the way we want it to, which is why we need to run tests.
Prototyping. If all previous processes were completed successfully, we need to create an internal testing environment first. At this stage, data scientists collaborate with developers on a demo version of the new feature.
New product creation. The integration of the new function or feature into the existing product is done in collaboration with marketers, designers and product managers. This step is necessary to make sure that the new feature addresses an existing customer pain point, or provides a novel solution.
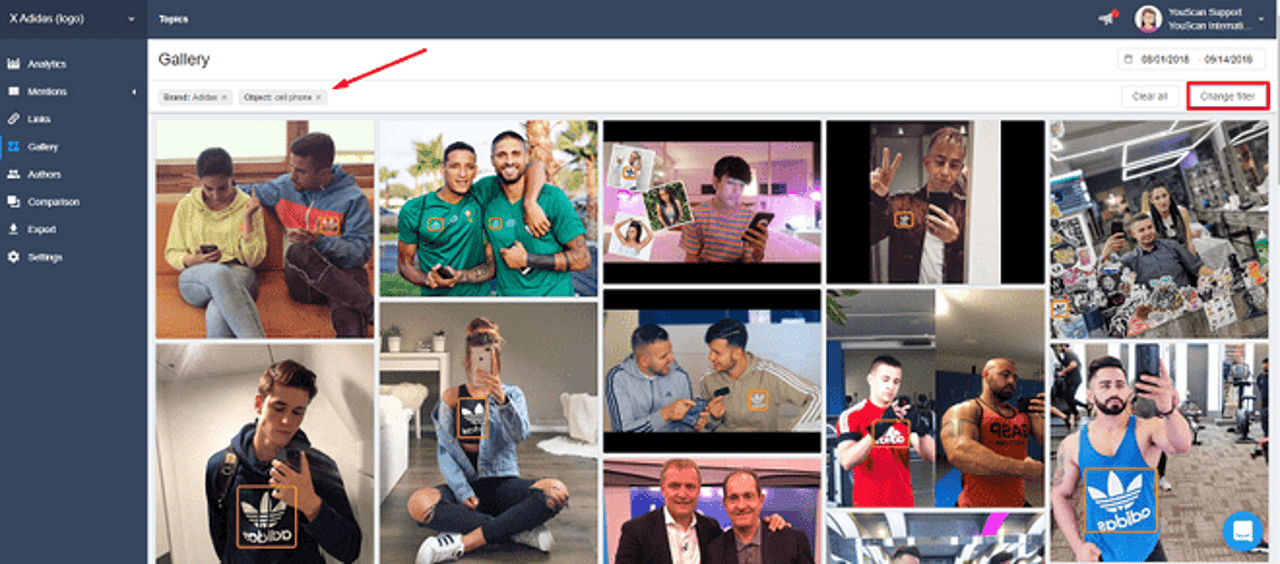
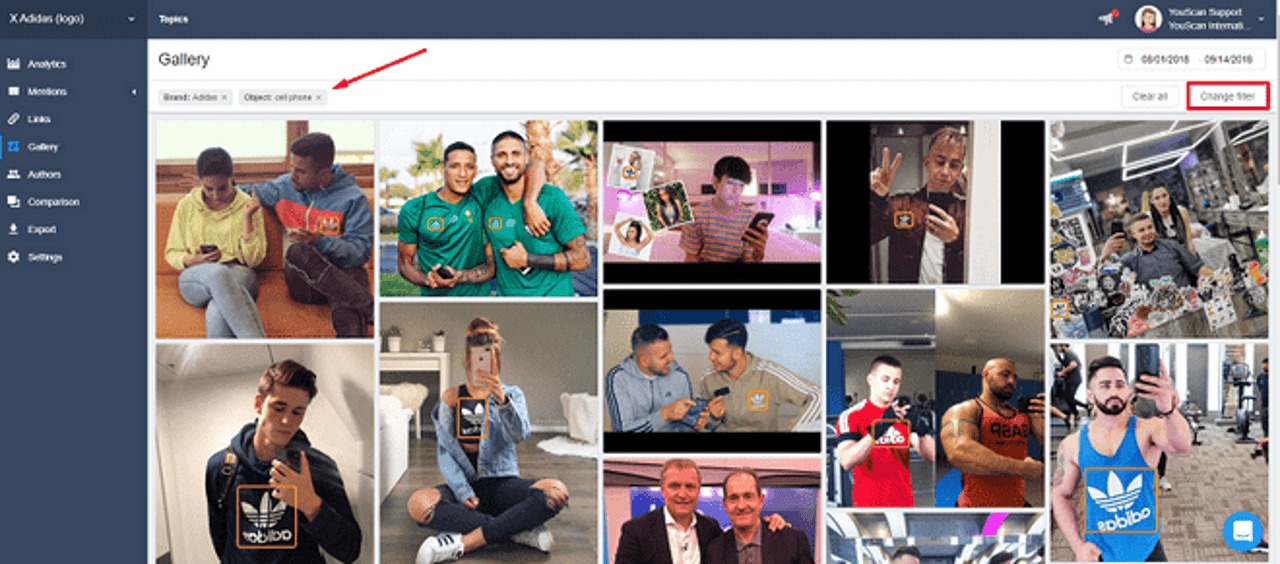
One of the latest features developed this way by our data scientists is the logo recognition function. Now we can find brand mentions on social media, even if there's no mention of it in the accompanying text - it's enough to have the brand's logo visible in the user's photos.
Sentiment analysis
One of the things our data scientists are investigating is sentiment analysis of social media posts. There are three types of sentiment, or the verbal expression of one's opinion about something: positive, neutral, or negative. The problem with the kind of content we work with is that "live" social media content can vary. Expressions of positive or negative feelings can be subtle, and when people use sarcasm or irony, things get even more complicated.
Furthermore, it's important to analyze the context of the post. For example, a cleaning product that leaves your dishes clean and shiny is a good thing, while a similar post about Coca-Cola is not so good - it's unlikely that the beverage company wants to be associated with household cleaners. Such subtleties can be addressed by using deep learning neural networks with recurring memory layers. In these cases, we develop algorithms designed to detect context, identify discussion subjects and topics.
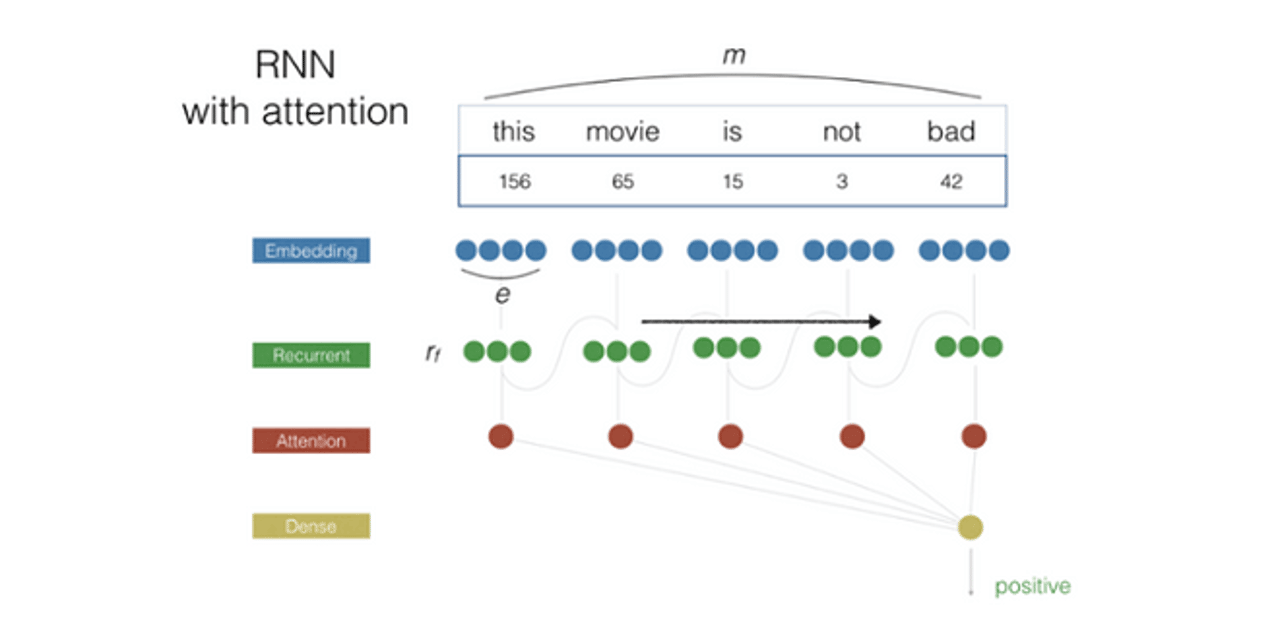
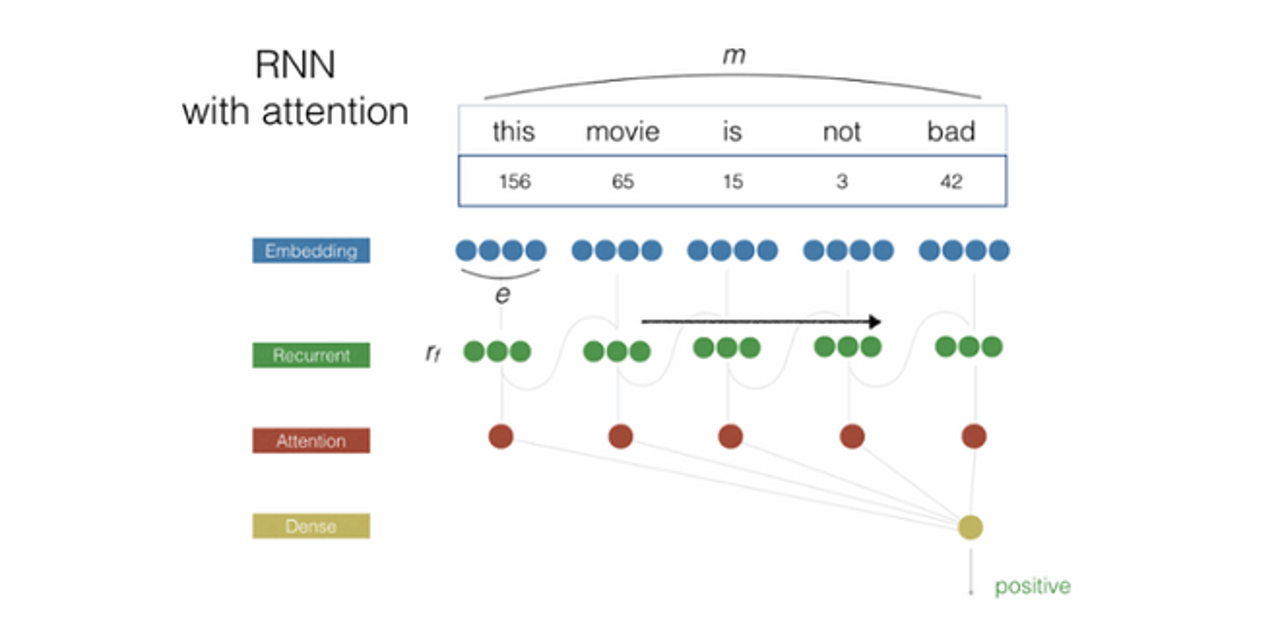
Our new model, based on recurring neural networks, is better at understanding the fine details of a mention, which has helped us significantly reduce the error rate of sentiment analysis. In these cases, data scientists are responsible for creating a rich training environment that can help the algorithms learn the subtleties of social media conversations. We are training the AI to detect sentiment for several brand categories, with considerations of their unique demands. This helps us achieve greater accuracy in sentiment detection.
Our inspiration sources
Data scientists at YouScan start their day with coffee and some light reading - usually, English-language publications, where the latest trends and news tend to appear first. For example, our colleagues find lots of neat information on Medium and on arxiv.org, which is an electronic archive of journal articles and abstracts from Cornell University. All of the latest trends in data science and machine learnings are usually published there.
The Russian community of data scientists usually hangs out in the ODS (Open Data Science) Slack channel. It currently has about 12,000 members, all helping each other. Our team also participates in the VK Deep Learning group, and actively comment in posts about their areas of expertise on Habrahabr.


The YouScan team at the #AIUkraine2016 conference


The 5th Moscow Data Fest. Data Fest is the biggest conference that connects researchers, engineers and developers working in data science, machine learning and artificial intelligence fields.
Interestingly, the majority of scientific articles from subject matter experts are open-source. For example, Google and Facebook provide detailed explanations of their new algorithms and make special announcements about their latest AI training models at various scientific conferences. This means we can both use the technology developed by the industry leaders, as well as customize it for our own tasks, like social media analysis. By the way, we are able to provide our Visual Insights and logo recognition services, the quality of which rivals those available on European and North American markets, at a much lower cost.
Content analysis tasks get more and more complicated each day. For example, nowadays, developers are working on teaching algorithms to analyze various video formats - from Facebook and VK Stories, to detailed analysis of entire YouTube channels. Videos are essentially sets of images, which are already being analyzed successfully by our algorithms. But now, there are many, many more of them to analyze.
So, do you feel like you know more about what data scientists do? There's more to learn about this and other fascinating topics on our blog. Follow us on Facebook, Twitter and LinkedIn to stay up to date!
.png)

.png)
