Новая модель автоматического определения тональности упоминаний: как это работает?


Тональность упоминаний — одна из основополагающих метрик при мониторинге социальных сетей, а автоматическое её определение помогает быстро и эффективно анализировать инфополе. Функция автоматического определения тональности существовала в YouScan уже очень давно, но сейчас мы подготовили самое масштабное, или даже (не побоимся этого слова) революционное её обновление за всю историю YouScan.
Новая модель все также объектно-ориентированная, но при этом использованы новейшие подходы на основе глубоких нейронных сетей. Более детально про модель и ее будущие возможности, которые находятся на стадии разработки, можно посмотреть в нашем докладе на самой большой Data Science конференции в СНГ (Data Fest 5)
Что означает «объектно-ориентированная модель»?
В одном сообщении может содержаться оценочное мнение о нескольких объектах в разных контекстах. Возьмем для примера такое упоминание Яндекс.Такси:
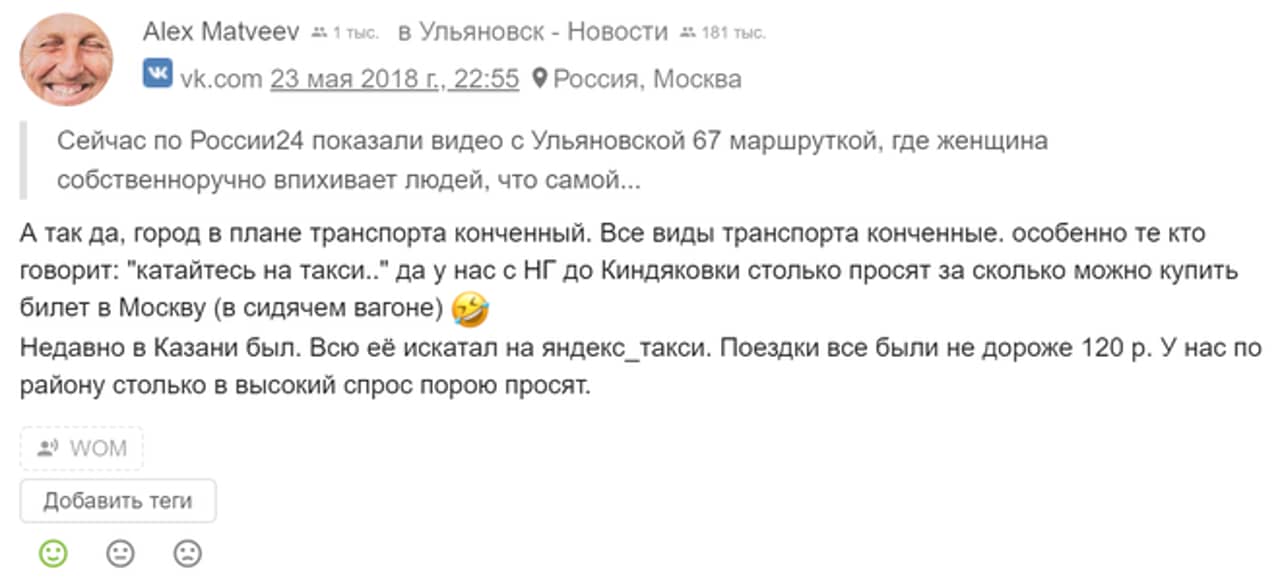
Само по себе сообщение несет более негативный окрас, чем позитивный, но в отношении Яндекс.Такси говорится, что этот сервис использовался в Казани, а цена и качество услуги устроили клиента. Таким образом правильно присвоить этому упоминанию позитивную тональность.
Алгоритм определения тональности автоматически находит объект мониторинга в тексте и определяет тональность не по всему тексту, а по тому фрагменту, который находиться рядом с объектом мониторинга. Когда речь идет о сравнении с конкурентами, то тональность будет получаться разной, в зависимости от того, какой именно бренд мониторится.


90 — 95% точности
Для обучения новой модели использовалась выборка из более чем 2 миллионов размеченных сообщений из разных отраслей: такси, онлайн-магазины, банки, лекарства, новости, политика, спорт, рестораны, напитки, товары массового использования и другие.
Точность определения позитивных и негативных упоминаний на данный момент составляет не менее 90%, а для хорошо размеченных тем (где было накоплено большое количество упоминаний с хорошо размеченной тональностью) — более 95%, что является State-Of-The-Art показателем для данной задачи.
Как модель умеет понимать контекст упоминания?
Еще одной сложностью при определении тональности является тот факт, что одни и те же слова могут иметь как негативный, так и позитивный оттенок в зависимости от того, о чем именно идет речь. Например, «Фейри помог хорошо отмыть грязную кастрюлю» — позитивное упоминание, но когда кто-то пишет, что «Coca-Cola помогла хорошо отмыть кастрюлю» — то это негатив, поскольку Coca-Cola никак не заинтересована в том, чтобы её бренд ассоциировался с моющим средством.
Наша новая модель определения тональности умеет справляться с подобными трудностями. В основе модели лежат глубокие нейронные сети с рекуррентными слоями памяти и слоями, которые выбирают на какой части сообщения концентрировать свое основное внимание в зависимости от контекста, объекта и тематики. Благодаря большой обучающей выборке мы смогли научить модель понимать о чем и как говорят в социальных сетях, чтобы хорошо определять тональность для разных брендов с учетом их специфики. Поэтому при наличии размеченных данных даже такие специфические кейсы, как в примере с Coca-Cola, не являются проблемой — модель будет их «понимать».
Обучается ли модель со временем?
Будет ли улучшаться качество работы модели в конкретных темах мониторинга, если размечать тональность в них вручную? Да, мы будем обновлять модель раз в месяц, дообучая её на новых данных для понимания новых трендов и неизвестных ранее сочетаний слов. Поэтому даже для сложных и новых отраслей мы за небольшой промежуток времени сможем очень существенно улучшить качество определения тональности упоминаний.
Многие наши клиенты уже успели познакомиться с работой новой модели на этапе её бета-тестирования, и мы уже получили от них крайне позитивные отклики. С сегодняшнего дня модель будет включена для всех аккаунтов, обращаем внимание, что в связи с этим возможен скачок в количественных показателях. Старая модель был очень «консервативной» и определяла позитив или негатив только в случае высокой уверенности, наличия конкретных негативных слов. Новая модель обеспечивает намного большую полноту разметки позитива и негатива, поэтому на большинстве тем с автоматической разметкой будет заметен рост показателей как по позитивной, так и по негативной тональности. Пожалуйста, учтите это при анализе данных.
Будем рады любой обратной связи по поводу работы новой модели от наших клиентов. А, если вы ещё не наш клиент — оставьте заявку на демо, и вы сможете сами протестировать как можно автоматически отслеживать позитивные и негативные упоминания вашего бренда.
-1669931544.png)
-1669652493.png)
-1640363177-1645191455.png)
